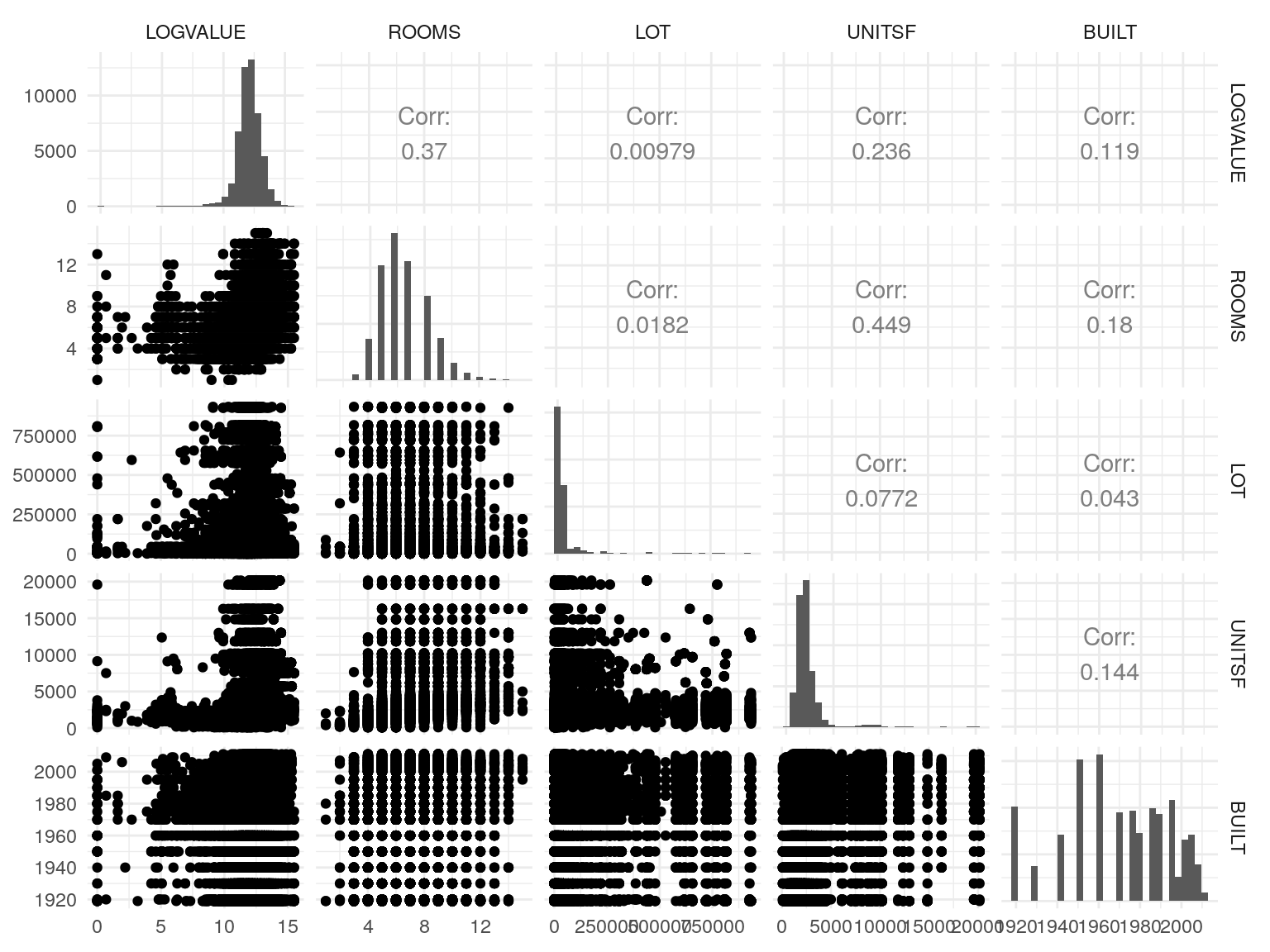
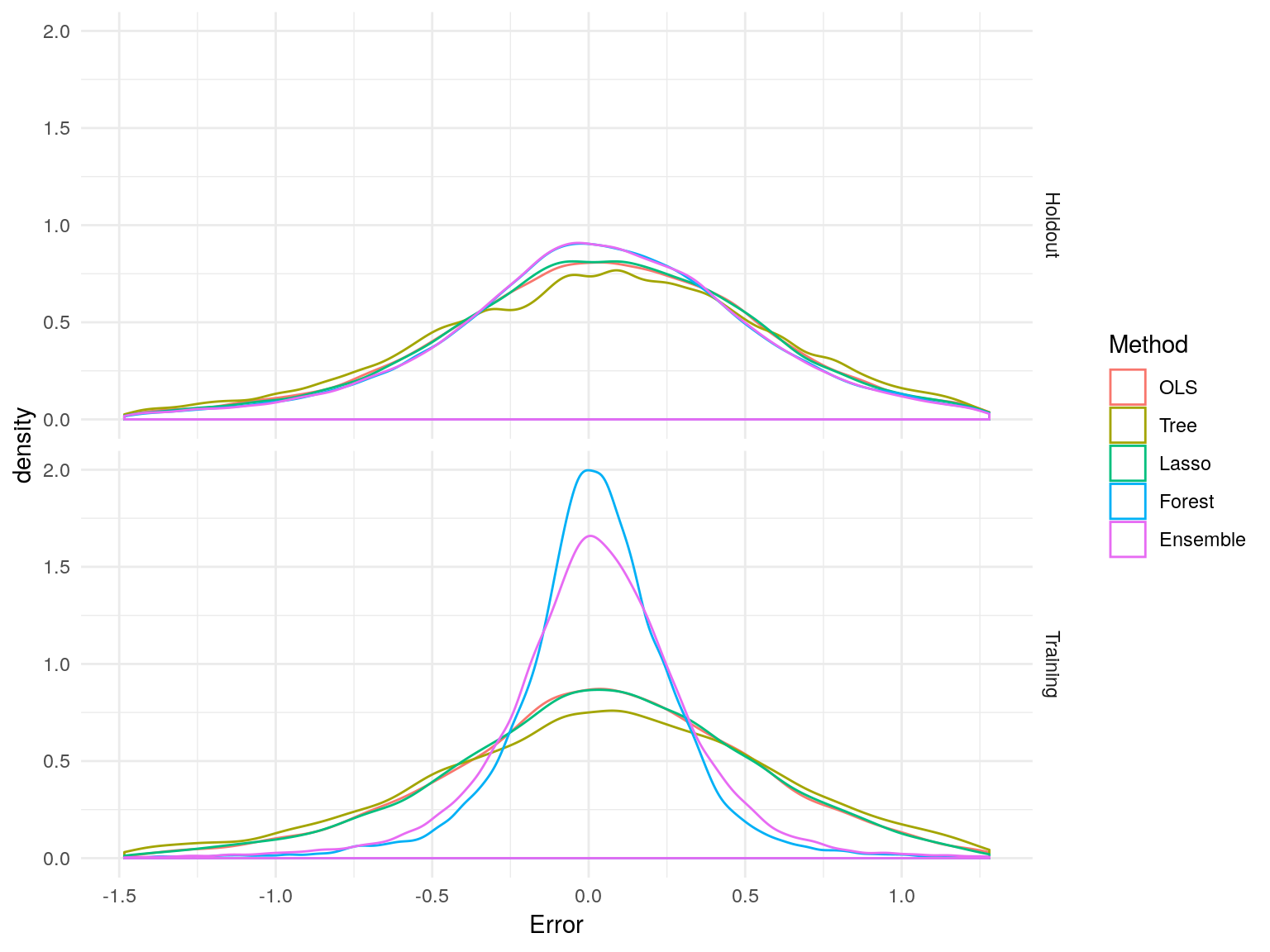
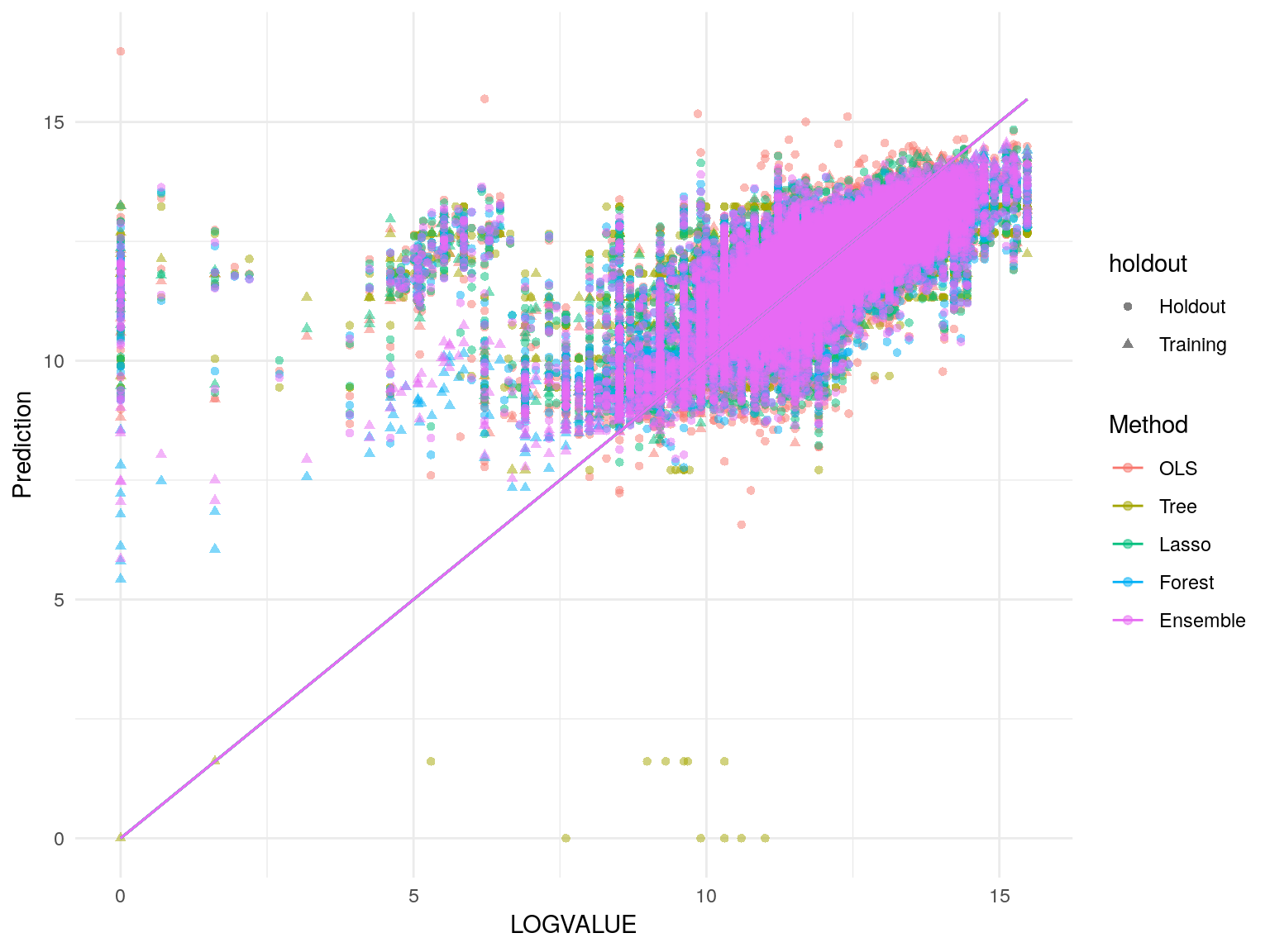
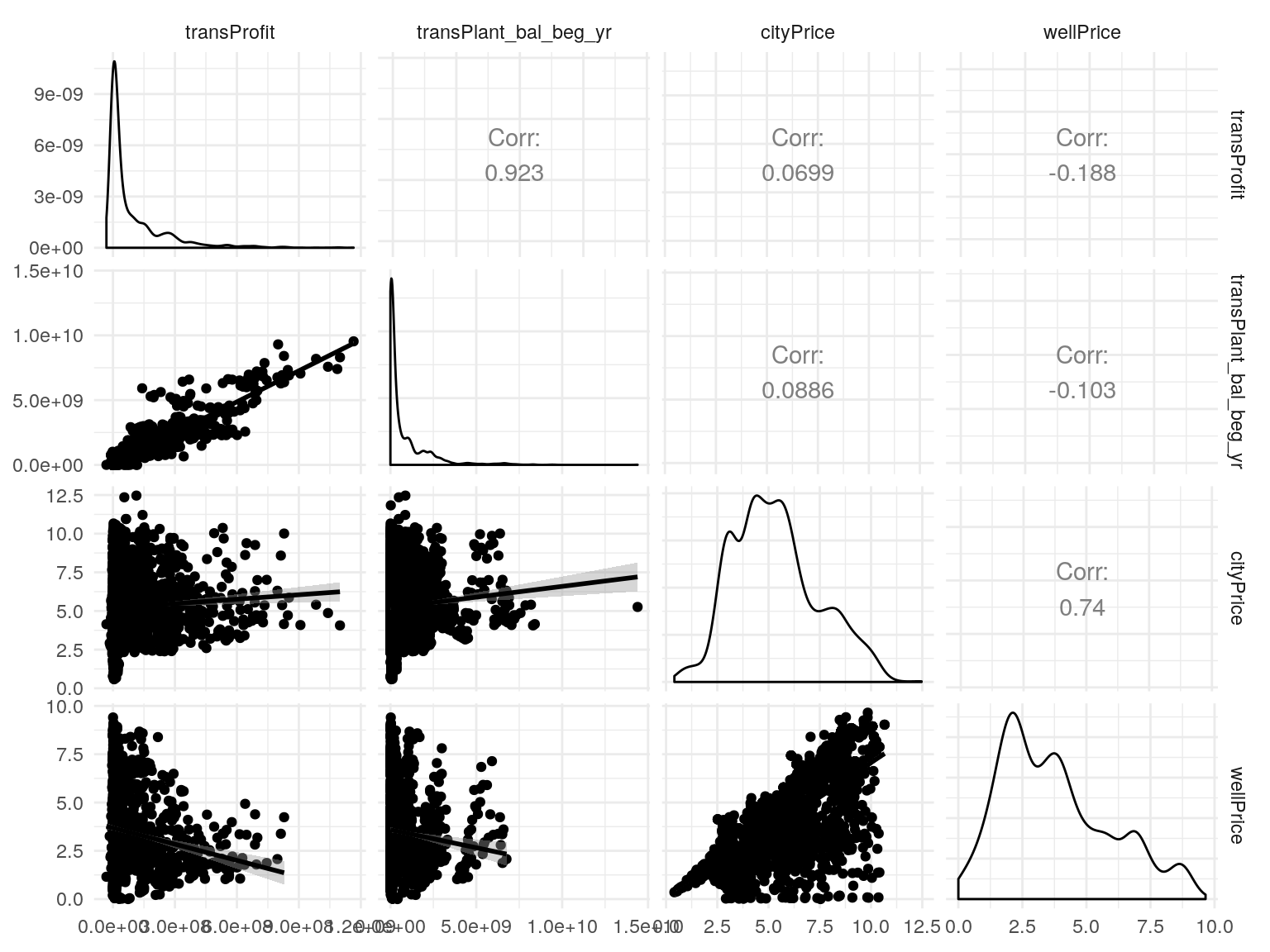
Angrist, Joshua D., and Alan B. Krueger. 1991. “Does Compulsory School Attendance Affect Schooling and Earnings?” The Quarterly Journal of Economics 106 (4). Oxford University Press: pp. 979–1014. http://www.jstor.org/stable/2937954.
———. 2016. “Recursive Partitioning for Heterogeneous Causal Effects.” Proceedings of the National Academy of Sciences 113 (27). National Academy of Sciences: 7353–60. https://doi.org/10.1073/pnas.1510489113.
Athey, Susan, Guido Imbens, Thai Pham, and Stefan Wager. 2017. “Estimating Average Treatment Effects: Supplementary Analyses and Remaining Challenges.” American Economic Review 107 (5): 278–81. https://doi.org/10.1257/aer.p20171042.
Athey, Susan, and Guido W. Imbens. 2017. “The State of Applied Econometrics: Causality and Policy Evaluation.” Journal of Economic Perspectives 31 (2): 3–32. https://doi.org/10.1257/jep.31.2.3.
Barron, A. R. 1993. “Universal Approximation Bounds for Superpositions of a Sigmoidal Function.” IEEE Transactions on Information Theory 39 (3): 930–45. https://doi.org/10.1109/18.256500.
Belloni, A., D. Chen, V. Chernozhukov, and C. Hansen. 2012. “Sparse Models and Methods for Optimal Instruments with an Application to Eminent Domain.” Econometrica 80 (6): 2369–2429. https://doi.org/10.3982/ECTA9626.
Belloni, A., V. Chernozhukov, I. Fernández-Val, and C. Hansen. 2017. “Program Evaluation and Causal Inference with High-Dimensional Data.” Econometrica 85 (1): 233–98. https://doi.org/10.3982/ECTA12723.
Belloni, Alexandre, and Victor Chernozhukov. 2011. “High Dimensional Sparse Econometric Models: An Introduction.” In Inverse Problems and High-Dimensional Estimation: Stats in the Château Summer School, August 31 - September 4, 2009, edited by Pierre Alquier, Eric Gautier, and Gilles Stoltz, 121–56. Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-642-19989-9_3.
Belloni, Alexandre, Victor Chernozhukov, Denis Chetverikov, Christian Hansen, and Kengo Kato. 2018. “High-Dimensional Econometrics and Regularized Gmm.” https://arxiv.org/abs/1806.01888.
Belloni, Alexandre, Victor Chernozhukov, Denis Chetverikov, and Ying Wei. 2018. “Uniformly Valid Post-Regularization Confidence Regions for Many Functional Parameters in Z-Estimation Framework.” Ann. Statist. 46 (6B). The Institute of Mathematical Statistics: 3643–75. https://doi.org/10.1214/17-AOS1671.
Belloni, Alexandre, Victor Chernozhukov, and Christian Hansen. 2014a. “Inference on Treatment Effects After Selection Among High-Dimensional Controls†.” The Review of Economic Studies 81 (2): 608–50. https://doi.org/10.1093/restud/rdt044.
Breiman, Leo, and others. 2001. “Statistical Modeling: The Two Cultures (with Comments and a Rejoinder by the Author).” Statistical Science 16 (3). Institute of Mathematical Statistics: 199–231. https://projecteuclid.org/euclid.ss/1009213726.
Carrasco, Marine, Jean-Pierre Florens, and Eric Renault. 2007. “Chapter 77 Linear Inverse Problems in Structural Econometrics Estimation Based on Spectral Decomposition and Regularization.” In, edited by James J. Heckman and Edward E. Leamer, 6:5633–5751. Handbook of Econometrics. Elsevier. https://doi.org/https://doi.org/10.1016/S1573-4412(07)06077-1.
Chen, Xiaohong, and H. White. 1999. “Improved Rates and Asymptotic Normality for Nonparametric Neural Network Estimators.” IEEE Transactions on Information Theory 45 (2): 682–91. https://doi.org/10.1109/18.749011.
Chernozhukov, Victor, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, and Whitney Newey. 2017. “Double/Debiased/Neyman Machine Learning of Treatment Effects.” American Economic Review 107 (5): 261–65. https://doi.org/10.1257/aer.p20171038.
Chernozhukov, Victor, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018. “Double/Debiased Machine Learning for Treatment and Structural Parameters.” The Econometrics Journal 21 (1): C1–C68. https://doi.org/10.1111/ectj.12097.
Chernozhukov, Victor, Mert Demirer, Esther Duflo, and Iván Fernández-Val. 2018. “Generic Machine Learning Inference on Heterogenous Treatment Effects in Randomized Experimentsxo.” Working Paper 24678. Working Paper Series. National Bureau of Economic Research. https://doi.org/10.3386/w24678.
Chernozhukov, Victor, Matt Goldman, Vira Semenova, and Matt Taddy. 2017. “Orthogonal Machine Learning for Demand Estimation: High Dimensional Causal Inference in Dynamic Panels.” https://arxiv.org/abs/1712.09988v2.
Chernozhukov, Victor, Whitney Newey, and James Robins. 2018. “Double/de-Biased Machine Learning Using Regularized Riesz Representers.” https://arxiv.org/abs/1802.08667.
Connors, Alfred F., Theodore Speroff, Neal V. Dawson, Charles Thomas, Frank E. Harrell Jr, Douglas Wagner, Norman Desbiens, et al. 1996. “The Effectiveness of Right Heart Catheterization in the Initial Care of Critically Ill Patients.” JAMA 276 (11): 889–97. https://doi.org/10.1001/jama.1996.03540110043030.
Donoho, David L., and Iain M. Johnstone. 1995. “Adapting to Unknown Smoothness via Wavelet Shrinkage.” Journal of the American Statistical Association 90 (432). [American Statistical Association, Taylor & Francis, Ltd.]: 1200–1224. http://www.jstor.org/stable/2291512.
Hartford, Jason, Greg Lewis, Kevin Leyton-Brown, and Matt Taddy. 2017. “Deep IV: A Flexible Approach for Counterfactual Prediction.” In Proceedings of the 34th International Conference on Machine Learning, edited by Doina Precup and Yee Whye Teh, 70:1414–23. Proceedings of Machine Learning Research. International Convention Centre, Sydney, Australia: PMLR. http://proceedings.mlr.press/v70/hartford17a.html.
Lee, Jason D., Dennis L. Sun, Yuekai Sun, and Jonathan E. Taylor. 2016. “Exact Post-Selection Inference, with Application to the Lasso.” Ann. Statist. 44 (3). The Institute of Mathematical Statistics: 907–27. https://doi.org/10.1214/15-AOS1371.
Mullainathan, Sendhil, and Jann Spiess. 2017. “Machine Learning: An Applied Econometric Approach.” Journal of Economic Perspectives 31 (2): 87–106. https://doi.org/10.1257/jep.31.2.87.
Nickl, Richard, and Sara van de Geer. 2013. “Confidence Sets in Sparse Regression.” Ann. Statist. 41 (6). The Institute of Mathematical Statistics: 2852–76. https://doi.org/10.1214/13-AOS1170.
Rosenbaum, Paul R., and Donald B. Rubin. 1983. “The Central Role of the Propensity Score in Observational Studies for Causal Effects.” Biometrika 70 (1): 41–55. https://doi.org/10.1093/biomet/70.1.41.
Speckman, Paul. 1985. “Spline Smoothing and Optimal Rates of Convergence in Nonparametric Regression Models.” The Annals of Statistics 13 (3). Institute of Mathematical Statistics: 970–83. http://www.jstor.org/stable/2241119.
Stone, Charles J. 1982. “Optimal Global Rates of Convergence for Nonparametric Regression.” The Annals of Statistics 10 (4). Institute of Mathematical Statistics: 1040–53. http://www.jstor.org/stable/2240707.
Taylor, Jonathan, and Robert Tibshirani. 2017. “Post-Selection Inference for -Penalized Likelihood Models.” Canadian Journal of Statistics 46 (1): 41–61. https://doi.org/10.1002/cjs.11313.
Wager, Stefan, and Susan Athey. 2018. “Estimation and Inference of Heterogeneous Treatment Effects Using Random Forests.” Journal of the American Statistical Association 0 (0). Taylor & Francis: 1–15. https://doi.org/10.1080/01621459.2017.1319839.